World's most unique
entity resolution algorithm
In the digital world of today, the Information about customers is streaming into the enterprises business sytems through various channels forcing the organization to extract it piece by piece to resolve the customer's identity. Every interaction requires someone to piece together parts of the puzzle. Organizations therefore need to have a robust entity resolution mechanism to deal with the digital data in realtime.

Entity Resolution is vital for many sectors like law enforcement agencies, banking industry, allotment of unique number , transaction grouping and generation of profiles of individuals etc. Entity Resolution is often inbuilt into the software systems for searching and matching entities.
Presenting PrimeMatch which is the world's most unique algorithm for name matching based on mathematical modelling of a string matching exercise.
Most Entity Resolution solutions involve character based matching of name and fathers name and matching of date of birth. Entity Resolution which is a part of text search and text retrieval has lot of research interest. Most of the early published work on name matching was done by the statistics community addressing the record linkage problem, that is, the task of identifying duplicate records in databases.Proprietary solutions are available that are broadly classified as Exact Name Searches, Searching With Wild cards, Keying Partial Words, Text Retrieval Software, Use of Standard name bins, fuzzy namematching etc. to ensure uniqueness. These use either phonetic coding or similarity metrics to determine a match. Phonetic codes are constructed for the searched text, while the database is previously indexed using those codes which act as hash keys. Different types of phonetic codes are used like soundex, NYSIS, metaphone, double metaphone, caverphone etc are available and are used. Other approach use is to use different types of textual similarity metric which calculate the similarity of two strings as number between 0 and 1. Value 0 means the strings are completely different. Value 1 means perfect match of the strings. Intermediate values correspond to a partial match. The similarity metrics include hamming distance, edit distance also known as Levenshtein distance, n-gram indexes, Ratcliff/Obershelp pattern recognition, Jaro-Winkler similarity etc.
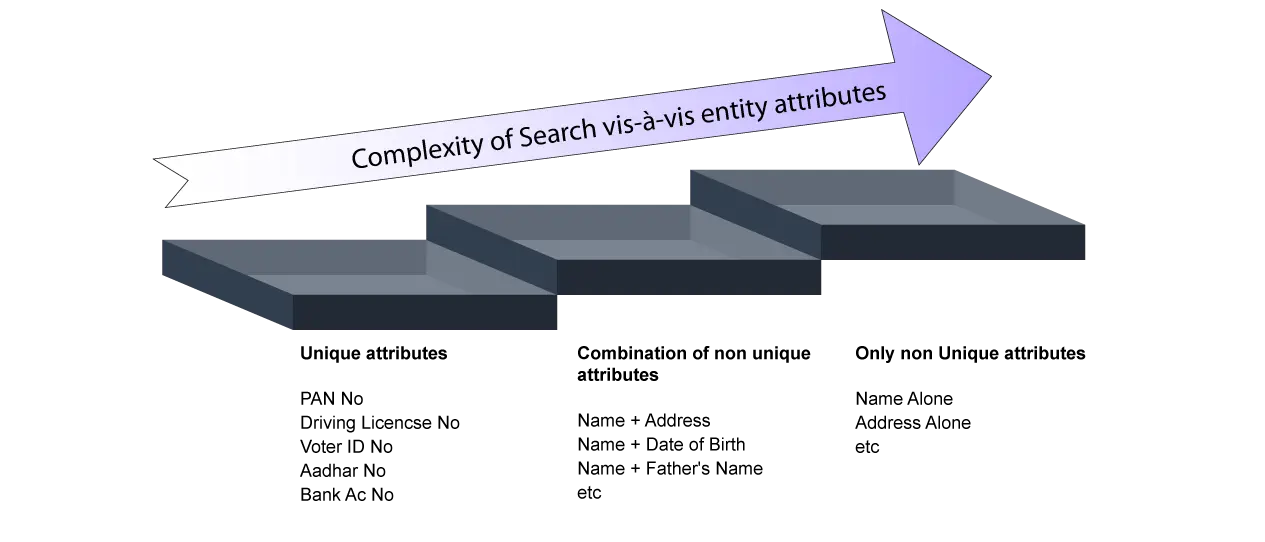
While understanding that matching either through phonetic coding or similarity metric is a pre requisite to detect the variations, a superior method of matching algorithm that overcomes all the types of variations and errors discussed earlier and at the same time very fast and less resource intensive particularly in large databases is a necessity. A new search and match engine called PrimeMatch was developed after extensive research and study over period of years. While it may be noted that there is no name matching algorithm that can give hundred percent results, the effort should be to reach the highest possible accuracy in the social identity process.
| Existing Solutions | PrimeMatch® |
|---|---|
| Phonetics (using existing phonetic algorithms) or Pattern Recognition (Edit distances, similarity metrics) | Phonetics (New phonetic algorithm) and Pattern Recognition (Mathematical equations) |
| Are designed for individual string matching. Do not have a comprehensive solution to match | A comprehensive solution to deal with name as an entity |
| Inability to handle most variations | Ability to handle most variations |
| Mostly Bin based or dictionary based | True match determination |
| Rigid Algorithms | Flexible Algorithm that allows for configuring the scope and depth of search |
| Limiting factor for handling huge data volumes | Handles huge data volumes easily |
| Character Comparison (Traditional Approach limiting precise matching) |
Number Comparison (Characters represented as numbers) (Innovative approach enabling precise matching) |
| Limiting factor for handling huge data volumes | Handles huge data volumes easily |